

Serverless : l'architecture qui fait disparaître les serveurs
Une application sans serveur : mais comment est-ce possible ? Découvrons ensemble cette architecture et comment elle peut rendre ton application plus scalable et flexible.

Commençons par expliquer le concept à ta grand-mère
Imagine que tu organises une grande fête chez toi. Normalement, tu dois acheter des chaises, des tables, préparer de la nourriture et t'assurer que tout est prêt pour accueillir tes invités. Mais avec le serverless, c'est comme si tu louais une salle de fête où tout est déjà prêt : les chaises, les tables, et même la nourriture. Tu n'as plus à t'inquiéter de tout préparer toi-même et en plus tu payes que ce qui a été utilisé et consommé par tes invités.
Let’s dive in !
Qu'est-ce que l'architecture serverless ?
L'architecture serverless permet aux développeurs d'exécuter du code sans se soucier de l'infrastructure sous-jacente. Les ressources sont allouées à la demande et s'adaptent dynamiquement au trafic, offrant une scalabilité automatique et un coût optimisé : vous ne payez que pour l'exécution effective du code.
Contrairement aux architectures traditionnelles, où des serveurs physiques ou virtuels doivent être provisionnés, configurés et maintenus, le serverless délègue ces tâches au fournisseur de services cloud (comme AWS, Azure ou Google Cloud). Dans un modèle classique avec des serveurs dédiés ou des machines virtuelles, il faut anticiper la charge, prévoir des mécanismes de mise à l'échelle et assurer la maintenance, ce qui engendre plus de complexité et de coûts fixes. Le serverless élimine ces contraintes, permettant aux développeurs de se concentrer sur l'écriture de code plutôt que sur la gestion de l'infrastructure.
Chez Amazon les applications serverless fonctionnent principalement grâce à deux services :
AWS Lambda est un service de calcul sans serveur qui permet d'exécuter du code en réponse à des événements sans avoir à provisionner ou gérer des serveurs. Vous écrivez simplement votre code (en Python, Node.js, Java, etc.) et Lambda s'occupe de tout le reste, y compris l'allocation des ressources, la mise à l'échelle automatique et la gestion de la haute disponibilité. Cela signifie que vous pouvez vous concentrer sur l'écriture de votre logique métier sans vous soucier de l'infrastructure sous-jacente.
Amazon DynamoDB est un service de base de données NoSQL entièrement géré qui offre des performances rapides et prévisibles à toute échelle. DynamoDB permet de stocker et de récupérer n'importe quelle quantité de données, et de gérer automatiquement le trafic de votre application en ajustant les capacités de lecture et d'écriture en fonction de la demande. Il est idéal pour les applications nécessitant des performances élevées et une mise à l'échelle automatique, telles que les applications mobiles, les jeux, les applications IoT et bien plus encore.
Ensemble, ce système de calcul et ce système de stockage forment une combinaison puissante pour construire des applications serverless qui sont à la fois évolutives et faciles à gérer.
L’exemple d’une application de réservation de spectacles
Imaginons que l’on soit Product Manager d’une application de réservation de spectacle que l’on va appeler BilletsPasCher 😉 L’architecture de notre application pourrait ressembler à celle décrite par le schéma ci-dessous :
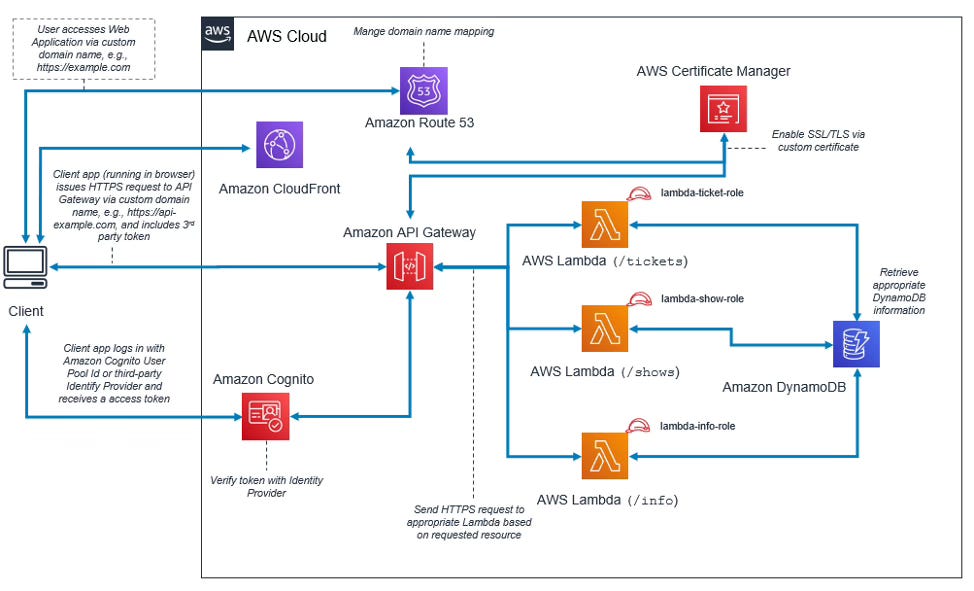
Si vous voulez comprendre en détail ce schéma, vous pouvez vous référer à mon précédent article sur les bases de l’infrastructure. Ce qui nous intéresse ici c’est la partie AWS Lambda et DynamoDB.

Lorsqu’un utilisateur va sur billetspascher.fr/shows pour voir la liste des spectacles disponibles, la requête va arriver jusqu’au service AWS Lambda en charge de cette partie qui va alors la traiter. Pour ce faire, elle va communiquer avec la base de données DynamoDB pour récupérer les informations.
En temps normal, l’instance Lambda ne s’exécute que lorsque qu’il y a une requête mais en cas de pic de charge il va y avoir un scale automatique géré par AWS qui va dupliquer autant que nécessaire les instances pour pouvoir répondre à la grande quantité de requêtes. DynamoDB va faire de même pour qu’il n’y ai pas de congestion au niveau de l’accès à la donnée brute. Une fois le pic passé le nombre d’instance va revenir à son état initial. Cela permet de garantir la performance d’une application peu importe le nombre d’utilisateurs.
Et d’un point de vue Product ?
En tant que Product Manager, l'architecture serverless offre plusieurs avantages, notamment pour les petites entreprises. Elle permet de développer des applications flexibles et modulaires, facilitant ainsi l'ajout de nouvelles fonctionnalités ou l'intégration de services tiers sans modifier l'infrastructure sous-jacente. Cette flexibilité réduit le time-to-market et aide à rester compétitif.
La scalabilité du serverless permet à votre application de s'adapter automatiquement à la demande, ce qui est particulièrement utile pour gérer l'augmentation du nombre d'utilisateurs ou les pics de trafic (comme les soldes pour une application e-commerce). Elle transforme également l'infrastructure en un coût variable en fonction de l'usage, réduisant ainsi les dépenses.
Comme il n'existe pas de solution miracle, l'architecture serverless présente aussi certains inconvénients. L'un des principaux est la dépendance accrue à votre fournisseur cloud, créant une "stickiness" importante. De plus, l'architecture serverless peut entraîner une complexité accrue de votre application et provoquer des latences dues à la nature distribuée des services.