



Logs : les yeux et les oreilles du monde du numérique !
Vous avez sûrement déjà été confronté à cette situation : le support vous signale un problème, et vos devs vous répondent avec un screenshot obscur en disant : “C’est dans les logs…”

Depuis cette semaine, vous êtes plus de 100 à être abonnés 🎉 Donc déjà merci beaucoup à vous. Et pour qu'on soit bientôt 200 n'hésitez pas à partager la publication à vos collègues, amis, connaissances PM et/ou à compléter le sondage sur ce que vous aimeriez avoir dans les prochaines éditions.
Aujourd’hui on va essayer de comprendre ensemble ce que sont les logs et en quoi le principe d’observabilité qui en découle est important pour votre produit.
Commençons par expliquer le concept à ta grand-mère
Imagine que tu as un journal où tu notes chaque chose importante qui se passe chez toi : les gens qui viennent, les repas que tu prépares, les réparations que tu fais. Les logs sont comme ce journal : ils enregistrent chaque événement dans une application. L’observabilité, c’est comme avoir un détective qui examine ce journal pour comprendre comment tout se passe et trouver des problèmes avant qu'ils ne deviennent graves.
Let’s dive in !
On va s’intéresser à deux concepts qui sont complémentaires : les logs et l’observabilité qu’ils permettent.
Les logs où comment garder une trace de ce qui se passe dans son application
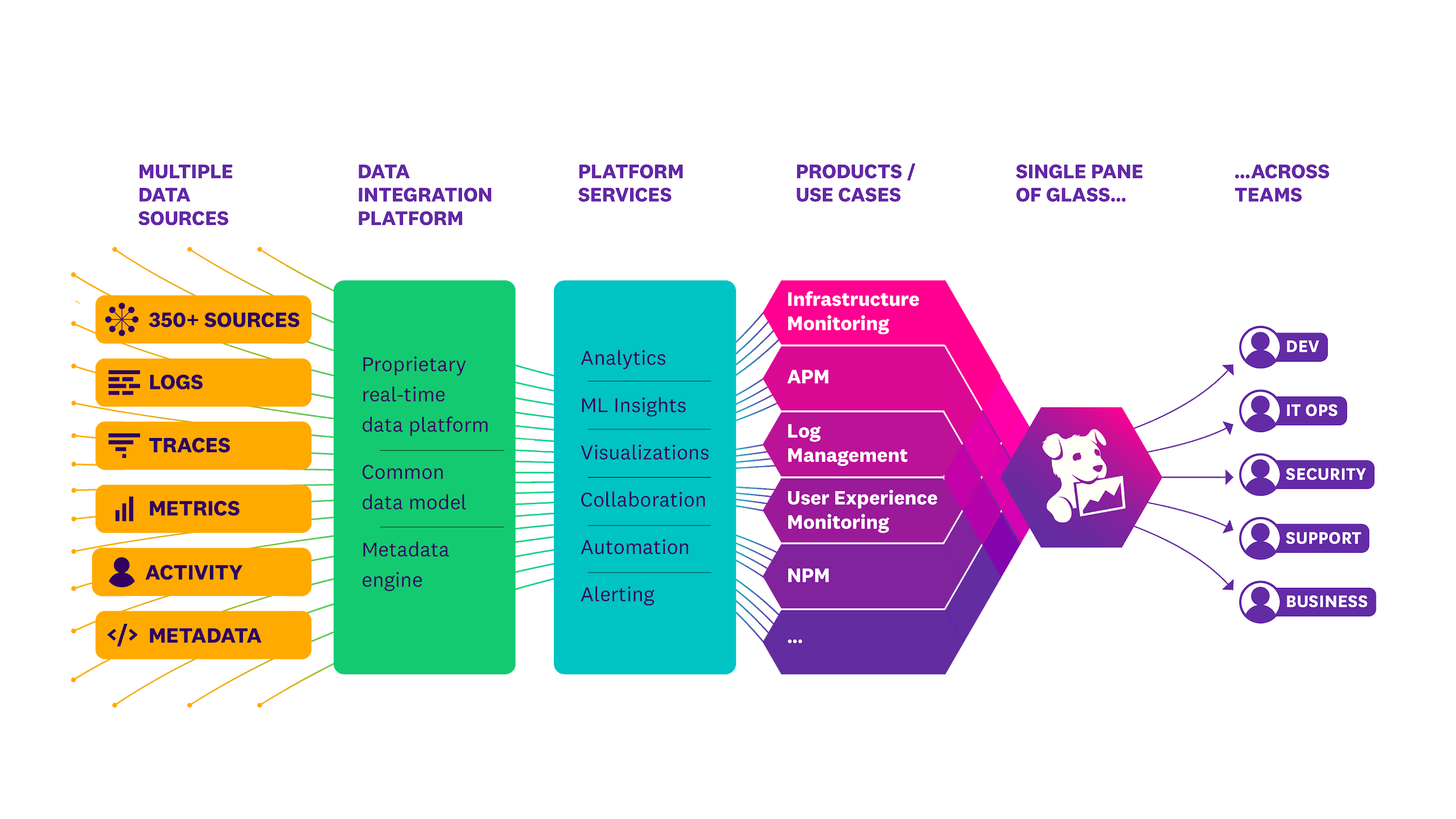
Les logs sont des enregistrements chronologiques des événements qui se produisent dans une application. Ils capturent des informations comme les erreurs, les avertissements, les informations de déboggage, et les événements utilisateur. Par exemple, on va stocker les informations comme la date, l’heure, l’adresse IP de chaque connexion à l’application ce qui permet d’avoir de la traçabilité.
Il existe plusieurs types de logs selon ce qu’ils enregistrent et l’objectif de ces enregistrement. On a par exemple les logs d’application qui vont enregistrer toutes les actions utilisateurs et les erreurs déclenchées mais aussi des logs de sécurité qui permettent de stocker des informations comme des tentatives de connexion ou des accès refusés.
Les logs sont générés, stockés, gérés et affichés grâce à différent outils :
Splunk : Une plateforme de gestion des logs qui permet de collecter, indexer et analyser les logs en temps réel.
Graylog : Une solution de gestion des logs open-source qui offre des fonctionnalités de collecte, de stockage et d'analyse des logs. Elle est souvent utilisée pour la surveillance des systèmes et la détection des anomalies.
ELK Stack (Elasticsearch, Logstash, Kibana) : Sûrement la plus connue c’est une suite d'outils open-source pour la gestion des logs. Elasticsearch stocke et indexe les logs, Logstash collecte et traite les logs, et Kibana fournit une interface utilisateur pour la visualisation des données.

Mais alors qu’est-ce que l’observabilité ?
L'observabilité, c’est la capacité à comprendre l'état interne d'un système basé sur les données qu'il génère, comme les logs mais aussi les métriques et les traces. Elle permet de diagnostiquer des problèmes, d'optimiser les performances et d'améliorer la fiabilité.
3 concepts composent le principe d’observabilité :
Les logs : Comme expliqué plus haut, les logs offrent un aperçu détaillé des événements qui se produisent dans le système.
Les métriques : Elles donnent une vue quantitative des performances du système, comme le temps de réponse, le taux d’erreurs, ou l’utilisation des ressources.
Les traces : Fournissent un suivi des requêtes à travers différentes parties du système, permettant d’identifier les goulets d’étranglement et de comprendre le flux des données.
Pour surveiller son application, on peut utiliser certains outils dédiés :
Datadog : Une plateforme de surveillance et d'analyse qui offre des fonctionnalités de collecte et d’analyse des métriques, des traces et des logs pour une vue complète de l’état de l’application.
Prometheus : Un outil open-source de surveillance et d'alerte qui collecte et stocke des métriques en temps réel.
Grafana : Une plateforme de visualisation open-source qui permet de créer des tableaux de bord interactifs pour surveiller les métriques et les logs, souvent couplée à Prometheus.
Et à quoi cela sert ?
Avoir une gestion des logs de qualité et permettre une bonne observabilité de son application à plusieurs utilités :
Détecter les anomalies : Surveillez les logs et les métriques pour repérer des anomalies telles que des pics d’erreurs ou des baisses de performance et ainsi pour réagir rapidement en limitant l’impact sur les utilisateurs
Débogguer : Les logs et les traces permettent de suivre tout le flux d’une action et ainsi de mieux comprendre d’où vient l’erreur.
Suivre les performances : Les métriques permettent surveiller l’utilisation des ressources, le temps de réponse, et la capacité à répondre aux demandes des utilisateurs et ainsi pouvoir scaler son application si nécessaire.
Et d’un point de vue Product ?
En tant que PM, comprendre les logs et l’observabilité peut vous aider à :
Créer un support ultra personnalisé : Si on va plus loin dans l’utilisation des logs, on peut même anticiper les tickets supports avant qu’ils soient rédigés par les clients voir même être pro-actif. C’est ce qui m’est arrivé plusieurs fois avec des outils comme Cycle (un outil de gestion de feedback). Et je dois dire qu’en tant qu’utilisateur, être prévenu de la résolution d’un bug qu’on avait même pas déclaré est très agréable.
Mieux communiquer avec vos devs : Bien comprendre les principes et les outils de l’observabilité vous permettra de mieux collaborer avec votre équipe technique notamment lors de la gestion d’incidents. En effet, si vous savez quels type de logs sont disponibles et où les trouver la discussion avec les devs sera bien plus facile dans des moments parfois stressants comme la gestion d’un incident de prod.
Prévenir les incidents : Et enfin les logs ça ne sert pas veulent à résoudre des incidents mais aussi à prévenir. En vous assurant que votre application est bien monitorée (il y a des outils en place et ces derniers sont regardés ou il y a des système d’alertes en place) vous vous assurez que tout est fait pour prévenir les incidents avant qu’il aient un impact fort.