


Le concept expliqué à quelqu’un qui découvre
Un coding assistant, c’est un petit peu comme un Thermomix, sauf qu’au lieu de faire des recettes, il écrit du code. La liste de recettes enregistrées, c’est un peu l’équivalent du modèle : il sait ce qu’il faut faire, mais il ne peut concrètement rien faire tout seul. Comme lui, le coding assistant a besoin d’outils pour pouvoir agir réellement.
Mais comme avec un Thermomix, tout dépend de ce que tu mets dedans. Le contexte, ce sont les ingrédients dans le bol : trop peu et le résultat est fade, trop et ça déborde. Le coding assistant accélère, sécurise et automatise les tâches répétitives, mais la recette, les arbitrages et le goût final restent entre les mains des devs. En clair : ce n’est pas lui qui fait le produit, c’est lui qui évite de rater la sauce 😉
Let’s dive in
La première chose à avoir en tête quand on parle de coding assistants, c’est que ce ne sont pas uniquement des modèles, mais des applications complexes dont le but est de transformer une requête utilisateur en une modification de code fonctionnelle.
Assistant = LLM + outils
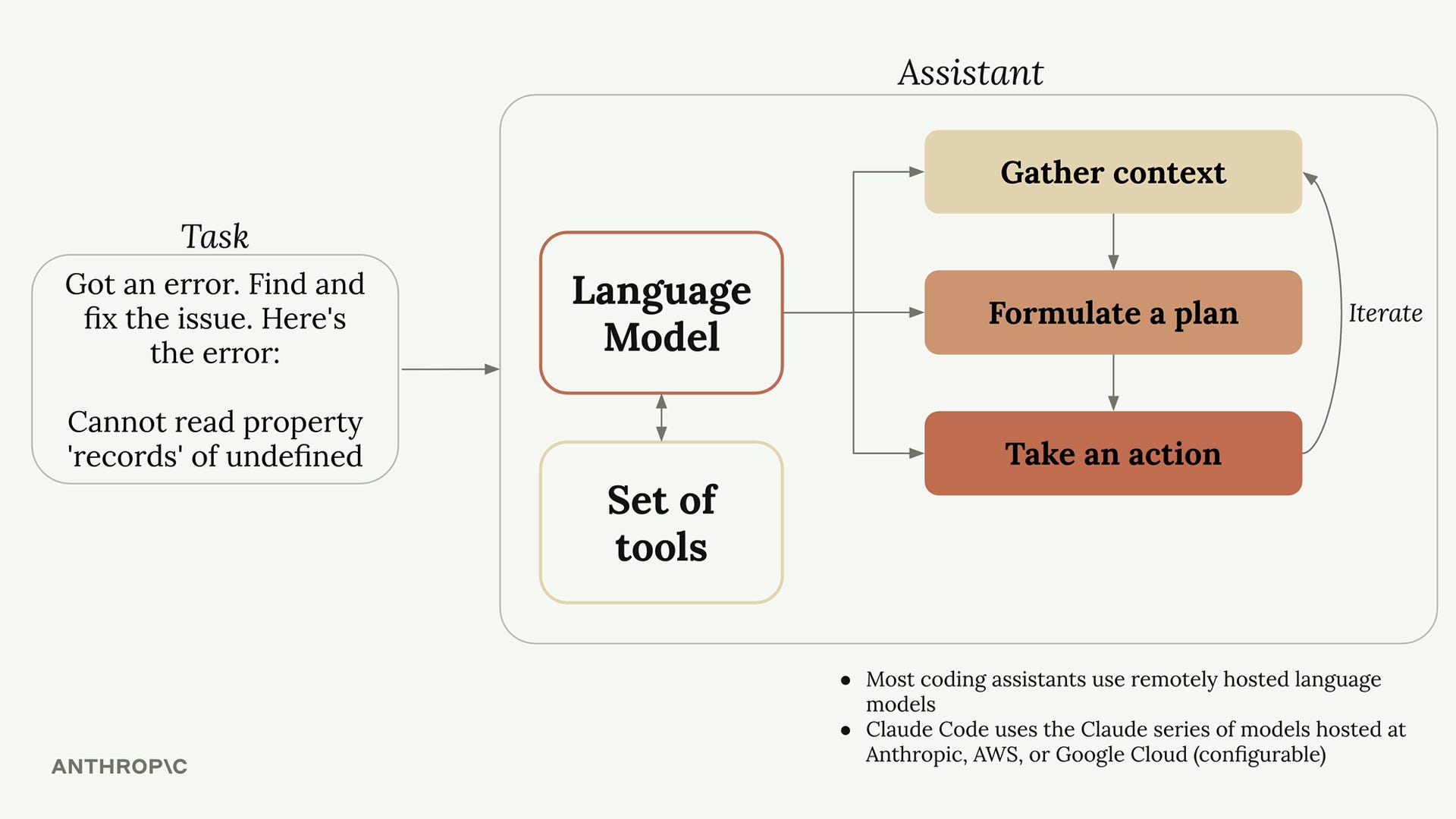
Pour comprendre globalement comment fonctionne un coding assistant, on peut regarder comment Anthropic (l’entreprise derrière Claude Code) l’explique : un modèle qui va avoir une réflexion itérative par rapport à une tâche donnée grâce à un ensemble d’outils. Regardons un peu plus en détail chacun de ces composants.
Le LLM
Le modèle (ou Large Language Model) est le moteur de la réflexion de l’assistant. Mais attention, le modèle ne “réfléchit” pas vraiment au sens humain. Un modèle, c’est un ensemble de patterns statistiques qui calcule des probabilités de prochain token.
Si on prend le cas d’un autocomplete (quand le coding assistant fonctionne en arrière-plan pour vous compléter au fur et à mesure que vous écrivez), où le dev aurait commencé à écrire function calculerTVA(prix) {, le modèle va analyser cet ensemble de caractères, calculer la probabilité du mot suivant et choisir le plus probable.
⚠️ Notre modèle n’a pas compris le code : il a seulement fait des mathématiques. C’est pour cela qu’un modèle peut complètement halluciner parfois : il est optimisé pour la plausibilité, pas pour la vérité.
Les outils
Mais un LLM est une IA text-to-text, c’est-à-dire qu’elle prend uniquement du texte en entrée et produit uniquement du texte en sortie. Seul, il ne peut donc rien faire dans un contexte de code.
C’est là qu’entrent en jeu les outils, qui sont un peu les bras du modèle et lui permettent de faire plus que réfléchir.
Les outils principaux que l’on retrouve dans les coding assistants permettent de :
lire un fichier
modifier un fichier
chercher des patterns dans un fichier
lancer une commande dans le terminal
faire une recherche sur Internet
etc.
Prenons un exemple concret :
Le modèle dit :
« Pour répondre, j’ai besoin de lire ce fichier »
Le coding assistant appelle l’outil
read_file, qui lit le contenu du fichierCe contenu est renvoyé au modèle
Le modèle peut enfin raisonner dessus et répondre
Pour faire simple : le modèle décide, l’outil agit.
Les autres concepts
Le contexte
Un modèle digère l’information sous forme de tokens, qui sont des morceaux de mots et représentent l’unité de base des modèles. C’est une notion importante, car tout est limité par des tokens.
Quand un dev utilise un assistant, il y a une limite physique d’entrée (input) et de sortie (output). Le modèle ne peut ingérer qu’une certaine quantité d’information à la fois.
Pour être pertinent, le modèle a besoin de contexte sur ce qu’on lui demande de faire. Ce contexte est globalement renvoyé avec chaque requête au modèle. Et oui, car un LLM est stateless, ce qui veut dire qu’il ne garde pas la mémoire de ce qu’il a fait. On doit donc constamment lui rappeler ce qu’il est en train de faire, ce qu’il a fait précédemment et le contexte de la demande.
La “taille de la mémoire” d’un LLM est ce qu’on appelle la context window, exprimée en nombre de tokens.
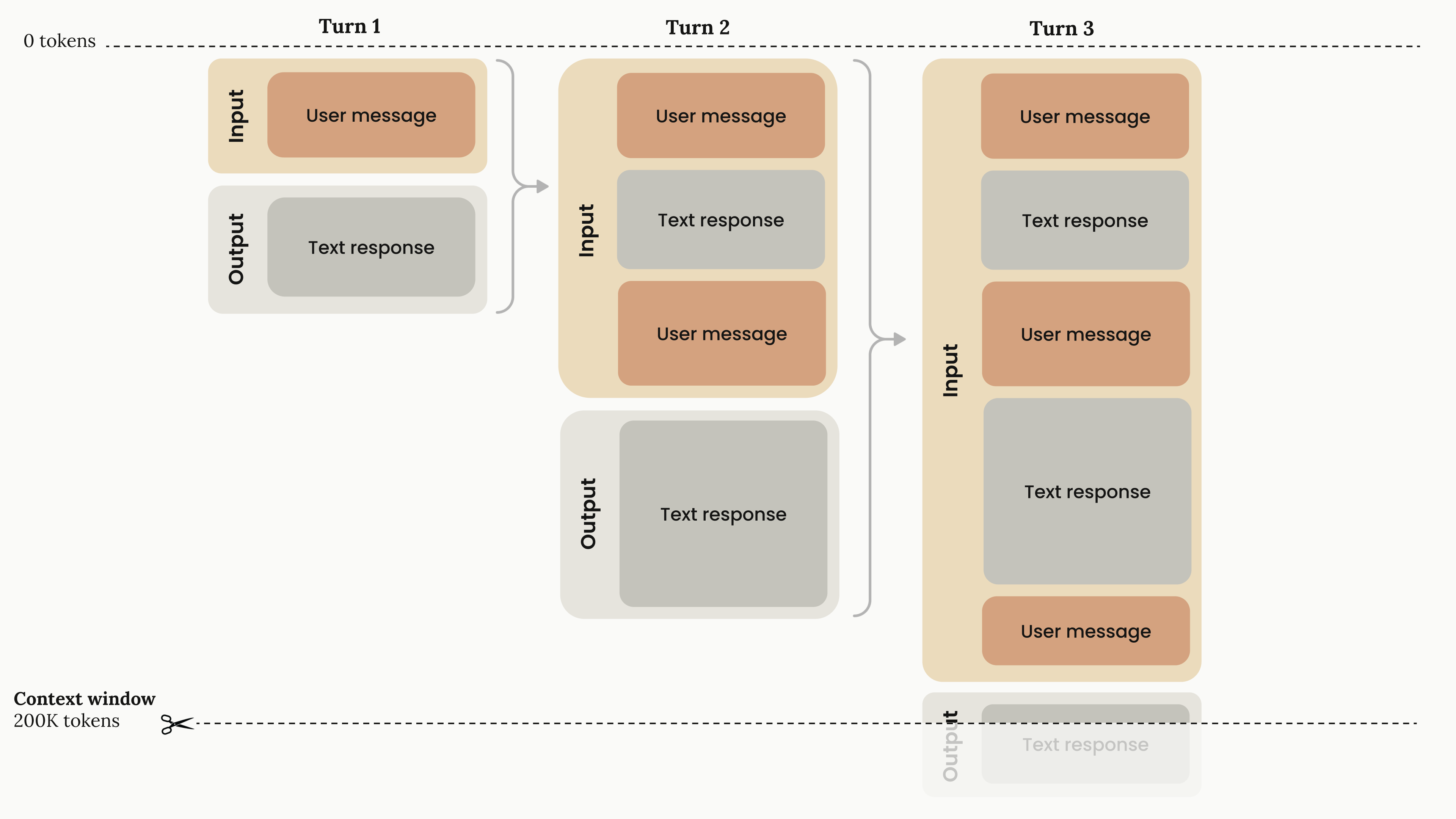
Les modèles actuels supportent des fenêtres de contexte d’environ 1 million de tokens, ce qui permet de travailler sur de grosses codebases.
Aussi, la plupart des assistants ont ajouté des outils de compactage pour éviter de “taper” toute cette fenêtre de contexte. Ces outils prennent l’ensemble de l’historique du chat et le remplacent par un résumé afin de libérer de l’espace.
L’indexation de la codebase
Même avec des fenêtres de contexte de plusieurs millions de tokens, le modèle ne peut pas connaître l’intégralité de votre codebase. C’est pour cela que la plupart des coding assistants proposent des fonctions d’indexation de la codebase.
Ces fonctions utilisent le principe de RAG (Retrieval-Augmented Generation) :
Indexation (embeddings) : l’outil scanne tout votre code et le transforme en vecteurs mathématiques. Le code qui se ressemble se retrouve proche dans cet espace vectoriel.
Recherche (retrieval) : quand le dev pose une question, l’outil cherche dans cet index les morceaux de code les plus pertinents.
Génération : ces morceaux sont injectés dans la context window du modèle, avec l’instruction :
« Utilise ces infos pour répondre à la question du dev ».
Le prompt système
Avant même que le dev ait commencé à écrire du code ou une demande, une instruction est envoyée par défaut au début de chaque requête : le prompt système.
Il sert à expliquer au modèle :
qu’il est utilisé dans le cadre d’un coding assistant
les bonnes pratiques à respecter
les langages à utiliser si rien n’est précisé
le ton à adopter dans ses réponses
etc.
MCP Servers
On ne les présente plus. Les MCP permettent de connecter le coding assistant au reste de l’écosystème. Il pourra ainsi générer du code à partir d’un PRD écrit sur Notion ou prendre en compte des commentaires faits sur une PR GitHub.
Et d’un point de vue Product ?
Les coding assistants sont en train de transformer en profondeur la façon dont on développe et dont les équipes travaillent. Et ce n’est probablement que le début. Bien utilisés, ils changent à la fois le quotidien des devs… et celui des PM.
Pour les développeurs, le premier gain est le focus. En déléguant la syntaxe, la configuration ou les détails de librairies, ils peuvent se concentrer sur ce qui compte vraiment : la logique business. Là où les derniers 10 % d’un développement prenaient souvent 50 % du temps, un assistant permet de débloquer rapidement la situation.
Ils jouent aussi un rôle clé dans la compréhension du code. Une codebase vit, évolue et accumule des années de décisions techniques. Un coding assistant aide à expliquer du code ancien ou complexe, à onboarder plus vite un junior et à réduire la dépendance à des personnes qui ne sont plus là.
Enfin, ils excellent sur les tâches peu gratifiantes mais indispensables : documentation, tests, scripts. Là où ces sujets sont souvent repoussés, l’IA permet de les produire rapidement et à moindre coût cognitif.
Résultat : une hausse significative de la vélocité des équipes, moins de blocages et plus de temps consacré à la valeur produit.
Pour les PM, la valeur est tout aussi concrète dans de nombreux scénarios dont voici quelques exemples :
Une question sur le fonctionnement d’une feature complexe non documentée ? Copilot est votre allié. Comme on l’entend souvent : « la meilleure documentation, c’est le code ». Sauf que vous, en tant que PM, n’avez pas forcément les connaissances pour aller y chercher la réponse. Ouvrez le repo avec un coding assistant, et il pourra très probablement vous répondre.
Vous devez sortir une donnée, votre data analyst est sous l’eau et vos cours de SQL remontent à loin ? Rien de mieux qu’un assistant pour vous écrire la requête.
Un bug simple à corriger, un script à écrire pour intégrer un outil ? Pourquoi ne pas essayer vous-même ? On a tous déjà vécu ce dilemme : un bug non urgent ou une micro-évolution à faire, mais impossible à prioriser côté dev. Dans ces moments-là, un coding assistant peut vous aider à devenir un junior developer pendant quelques minutes. Bien sûr, demandez l’accord de vos devs et respectez le process de review et de tests. L’idée est de contribuer, pas d’y aller en mode cowboy.
Mais cela comporte aussi de nombreux risque qu’il faut avoir en tête pour essayer de les anticiper et mettre des garde-fous :
Le risque de “code bloat” (l’obésité du code) Il est très facile de générer du code avec un assistant. Les devs peuvent alors être tentés de moins faire attention à l’architecture, d’ajouter trop de code ou d’en dupliquer, ce qui va, à terme, alourdir l’application et la rendre plus difficile à maintenir.
La sécurité et la qualité du code Les LLM sont connus pour générer du code qui n’est pas toujours de bonne qualité et/ou qui ne respecte pas les bonnes pratiques de sécurité, ce qui peut entraîner des risques majeurs. En parallèle de l’adoption d’un coding assistant, il est donc important de mettre en place des systèmes de vérification et de validation du code.
L’illusion de la compétence Un coding assistant peut donner l’impression d’être plus compétent qu’on ne l’est réellement, ce qui peut amener à produire du code très complexe. Au début, c’est génial… jusqu’au jour où il faut corriger un bug dans un code que personne ne comprend.
Les coding assistants ne remplacent ni les devs, ni les PM. Ils amplifient leurs capacités. Utilisés avec des garde-fous, des standards clairs et une vraie compréhension de ce qu’ils produisent, ils deviennent un levier puissant de productivité et de collaboration.
La clé n’est pas de coder plus vite, mais de coder mieux et surtout, de savoir quand faire confiance… et quand reprendre la main.

